[论文阅读] 机器学习驱动的椭偏测量
[论文阅读] 机器学习驱动的椭偏测量
论文标题:Machine learning powered ellipsometry
期刊:Light: Science & Applications (2021) 10:55
DOI:https://doi.org/10.1038/s41377-021-00482-0
作者:Jinchao Liu, Di Zhang, Dianqiang Yu, Mengxin Ren, Jingjun Xu(南开大学弱光非线性光子学重点实验室)
代码开源:没有开源
一、研究背景与问题
1.1 椭偏仪(Ellipsometry)简介
椭偏仪(Ellipsometry)是一种非接触、无损的光学测量技术,用于通过测量薄膜对光偏振态的改变来推导材料的光学常数(折射率 $n$ 和消光系数 $\kappa$)以及薄膜厚度 $d$。其物理原理建立在两百年前 Malus 和 Fresnel 的工作基础上。
椭偏仪测量 p 和 s 偏振分量之间的振幅比和相位差,定义椭偏角 $\Psi$ 和 $\Delta$
\[\tan\Psi \cdot e^{i\Delta} = \frac{r_p(n, \kappa, d)}{r_s(n, \kappa, d)}\]其中正问题(已知 $(n, \kappa, d)$ 求 $(\Psi, \Delta, R, T)$)已有精确解析解(Fresnel 公式 + Airy 多光束干涉公式);而逆问题(由测量数据反推 $(n, \kappa, d)$)则极为困难。
1.2 传统方法的局限性
-
病态逆问题(Ill-posed inverse problem):Airy 公式的超越性(transcendental nature)导致解析逆不可能,只能依赖迭代数值拟合。
-
多解歧义(Ambiguity):单对 $(\Psi, \Delta)$ 在薄膜厚度未知时,通常对应多组 $(n, \kappa, d)$ 解,无法唯一确定。
-
需要人工经验干预:传统拟合方法(如 EP4Model 等商业软件)需要专家手动选择合适的色散方程(Cauchy 模型、Sellmeier 模型、Forouhi-Bloomer 方程、Tauc-Lorentz 方程、Drude-Lorentz 模型等)并提供合理的初始猜测值,不然无法收敛,整个过程繁琐耗时。
-
传统辅助方法复杂:虽然引入透射率 T 和反射率 R 可以消除多解歧义,但传统方法无法高效地同时拟合 $(\Psi, \Delta, R, T)$ 四路信号,反而使问题更复杂。
-
前人 ANN 方法的不足:之前有研究(Urban & Tabet, 1994)用人工神经网络(ANN)预处理初始猜测值,但该方法只允许单次前向传播,没有”闭环反馈”和自动调整机制,存在因初始猜测不好而拟合失败的风险。
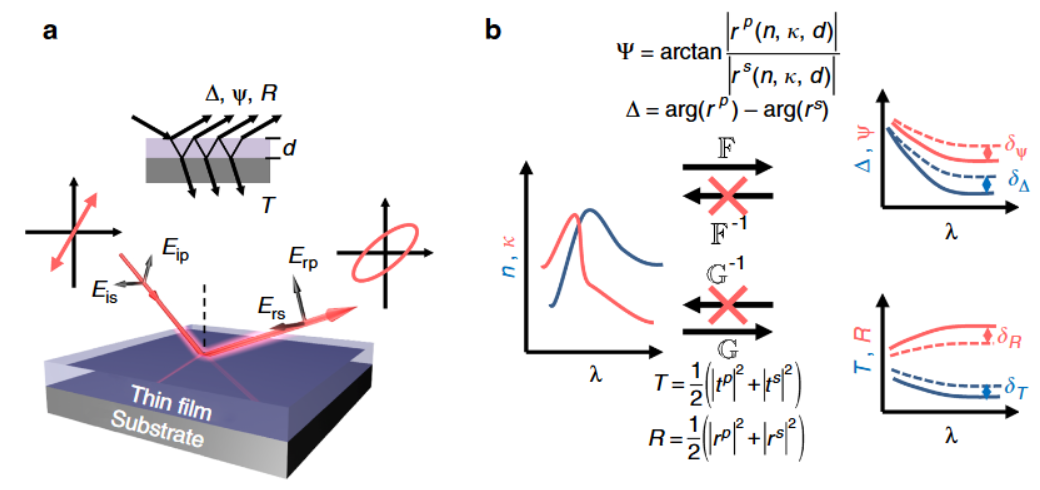
图一:对椭偏仪的求解原理与逆问题求解的困难性进行直观阐述。椭偏仪根据薄膜对不同偏振与入射角度光的不同响应,实现对材料nk值的反演
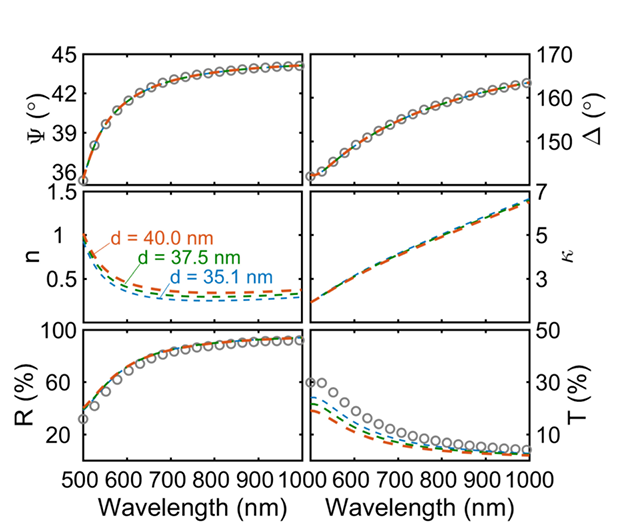
Fig S1.在固定$\Psi$和$\Delta$的情况下,根据厚度d不同,其可能存在对应多组nk组合的情况
二、核心创新点
2.1 方法论创新:SUNDIAL 框架
提出了基于深度神经网络迭代学习的椭偏仪分析方法,命名为 SUNDIAL(deep neural network-driven iterative learning for ellipsometry)。
三大核心创新:
-
全自动、无需人工干预:不需要专家提供初始猜测或选择色散模型,实现”单击即运行”的全自动椭偏分析。
-
同时拟合四路信号 $(\Psi, \Delta, R, T)$:传统方法只拟合椭偏角 $(\Psi, \Delta)$,而 SUNDIAL 将反射率 $R$ 和透射率 $T$ 作为互补信息同时输入,彻底消除多解歧义,获得唯一的 $(n, \kappa, d)$ 解。
-
迭代在线学习推理策略(Online iterative inference):提出了一种基于随机梯度下降的新颖迭代推理策略,解决了”模拟数据训练 → 真实实验数据推断”的域间差距(domain gap)问题,实现在线自适应。
2.2 技术创新:双模块闭环架构
网络由逆模块(inverse module)和正模块(forward module)形成闭环迭代,而非传统的单次前向传播。
2.3 实验验证创新
用覆盖金属、半导体、电介质三大类别的 15 种材料进行实验验证,展示了方法的广泛适用性。
三、研究方法与技术路线
3.1 数学问题建模
SUNDIAL 将椭偏反演问题定义为如下优化问题,记该式子为(1):
\[(n^*, \kappa^*, d^*) = \arg\min_{n,\kappa,d} \left[ \gamma \| F(n, \kappa, d) - (\Psi, \Delta) \|_2 + (1-\gamma) \| G(n, \kappa, d) - (R, T) \|_2 \right]\]其中:
-
$F(n, \kappa, d) - (\Psi, \Delta)$:椭偏正函数(基于 Fresnel + Airy 公式)
-
$G(n, \kappa, d) - (R, T)$:强度正函数
-
$\gamma \in [0, 1]$:两项之间的权重平衡系数,实验中取 $\gamma = 0.5$
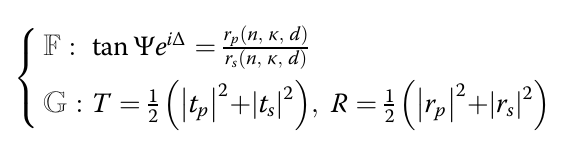
其中F和G指上述两个公式,$|·|_2$对应欧几里得范数(MSE)
3.2 数据来源
-
模拟数据:从 Palik 和 Sopra 数据库中取 200 种材料的 $(n, \kappa)$,利用正函数 $F$、$G$ 解析计算对应的 $(\Psi, \Delta, R, T)$ 光谱。厚度 $d$ 在 10~300 nm 范围内以 10 nm 步长变化(对金属等高损耗材料,厚度 < 100 nm 时步长为 5 nm),共生成 6240 个 $(\Psi, \Delta, R, T) \leftrightarrow (n, \kappa, d)$ 样本对,按 5240/500/500 划分为训练/验证/测试集。
-
实测物理数据:15 种薄膜材料(见下表),由椭偏仪和分光光度计分别采集 $(\Psi, \Delta)$ 和 $(R, T)$ 光谱。
| 类别 | 材料 | 制备方法 |
|---|---|---|
| 金属 | Au, Al, Cr, Co, Fe, Mo, Sc, W | 热蒸发 / 溅射 |
| 介电 | MgO, Si₃N₄, Ta₂O₅, TiN, TiO₂ | 热蒸发 / PECVD |
| 半导体 | Si | 热蒸发 |
| 相变材料 | Ge₂Sb₂Te₅ (GST) | 溅射 |
- 测量设备:椭偏仪(Imaging Ellipsometer EP4,Accurion Inc.,入射角 50°,可见光到近红外);透反射光谱仪(Spectrophotometer U-4100,Hitachi,正入射)。
四、机器学习模型架构(核心重点)
4.1 总体架构:双模块闭环
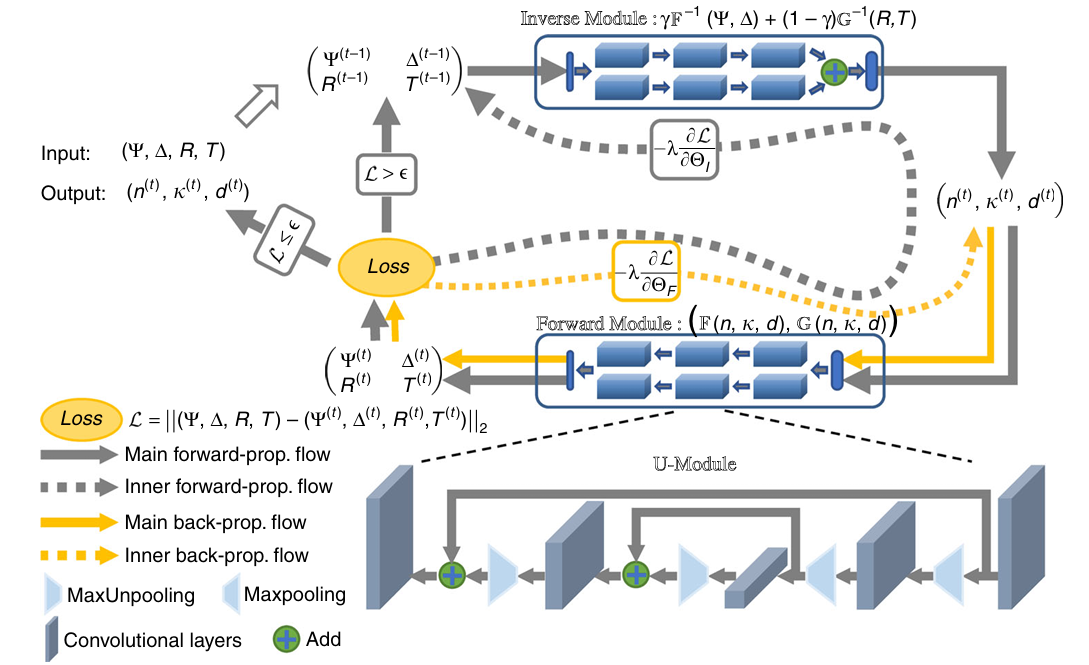
SUNDIAL 包含两大神经网络模块,构成闭合迭代循环,结构如上图所示,其大概的训练流程可以总结如下:
1.准备数据集
2.输入(n,k,d)组合,送入前向预测网络,网络预测对应的(Ψ, Δ, R, T) 光谱,计算上述公式(1)的误差,并梯度下降更新参数。多次训练迭代,直到残差r1<设定的误差值E1
3.固定前向预测网络权重,将反向网络与前向网络串在一起,同时将(Ψ, Δ, R, T)作为输入和预测目标,误差函数仍然一致,此时只更新反向网络的权重
2和3步反复迭代,直到两个网络都达到目标误差要求。
详细的公式与迭代训练过程如下所示:

4.2 Algorithm 1 详解
输入:实测的 $(\Psi, \Delta, R, T)$ 光谱;预训练好的 4 个正/逆网络权重 $\Theta_F$,$\Theta_I$;参数 $\alpha$(正网络学习率),$\beta$(逆网络学习率),$K$(内层迭代次数),$N$(外层最大迭代次数),阈值 $\epsilon_1$, $\epsilon_2$,权重 $\gamma$。
外层循环(t = 0 → N):
步骤 (a):生成邻域增强数据集 $\mathcal{D}^{(t)}$
- 用当前逆网络计算候选解 $x^{(t)}$: \(x^{(t)} = \frac{F^{-1}_{\Theta_{I,\Psi\Delta}}(\Psi, \Delta) + F^{-1}_{\Theta_{I,RT}}(R, T)}{2}\)
- 在 $x^{(t)}$ 邻域内随机采样若干点(每种增强策略采样 100 个,共 300 点 + 中心解,共约 301 个点)
- 用正解析函数 $F$、$G$ 计算这些邻域点对应的伪测量值 $(\Psi^{\mathcal{D}}, \Delta^{\mathcal{D}}, R^{\mathcal{D}}, T^{\mathcal{D}})$
- 得到增强数据集 $\mathcal{D}^{(t)}$
步骤 (b):更新正网络(Fine-tune Forward Network)
在增强数据集 $\mathcal{D}^{(t)}$ 上对正网络进行内层迭代训练(K 次),使其在当前解 $x^{(t)}$ 的邻域内更准确地近似正函数 $F$、$G$:
\[(\Theta_{F,\Psi\Delta}, \Theta_{F,RT})^{(k+1)} = (\Theta_{F,\Psi\Delta}, \Theta_{F,RT})^{(k)} - \alpha \cdot \nabla_{\Theta_F} \mathcal{L}_{\text{forward}}\]若残差 $r_1 < \epsilon_1$ 则停止内层迭代。
步骤 (c):固定正网络,更新逆网络
固定已微调的正网络权重 $\Theta_F^{(t)}$,将实测 $(\Psi, \Delta, R, T)$ 同时作为输入和目标,通过端到端反向传播更新逆网络权重:
\[(\Theta_{I,\Psi\Delta}, \Theta_{I,RT})^{(t+1)} = (\Theta_{I,\Psi\Delta}, \Theta_{I,RT})^{(t)} - \beta \cdot \nabla_{\Theta_I} \mathcal{L}_{\text{inverse}}\]损失函数: \(\mathcal{L} = \gamma \| (\Psi, \Delta) - F_{\Theta_{F,\Psi\Delta}}(x^{(t)}) \|_2 + (1-\gamma) \| (R,T) - F_{\Theta_{F,RT}}(x^{(t)}) \|_2\)
步骤 (d):收敛判断
若残差 $r_2 < \epsilon_2$,停止外层循环。
输出:具有最小残差 $r_2$ 的逆网络权重对应的输出: \(n^*, \kappa^*, d^* = \frac{F^{-1}_{\Theta^*_{I,\Psi\Delta}}(\Psi, \Delta) + F^{-1}_{\Theta^*_{I,RT}}(R, T)}{2}\)
4.3 运行时间
- 外层循环 $N$:取决于材料,50 至几百次不等
- 内层循环 $K = 10$
- 在配备 i7 CPU + NVIDIA GTX 1070 GPU(移动端)的笔记本电脑上:每个样本约 15 分钟至 1.5 小时(未经速度优化)
4.4 网络基础架构:堆叠残差 U 模块(Stacked Residual U-modules)
每个网络均采用堆叠残差 U 模块(Stacked Residual U-modules)作为 backbone,这是论文专门为此任务设计的架构:
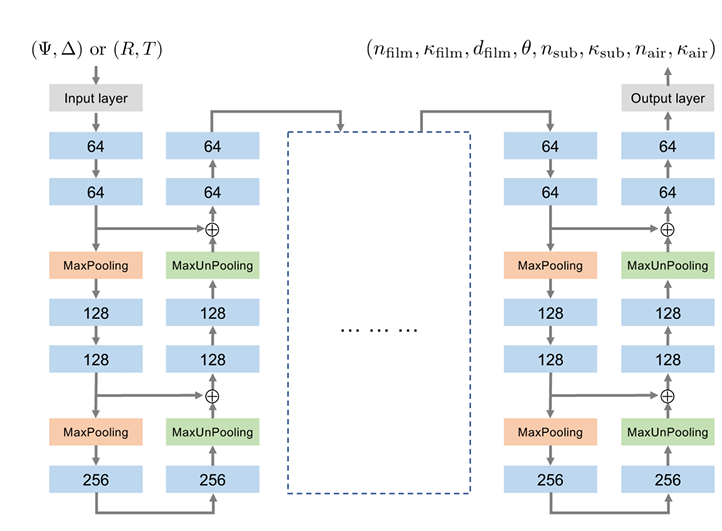
训练超参数:
- 优化器:ADAM(学习率 $10^{-4}$,权重衰减 $10^{-5}$)
- 学习率策略:余弦退火(Cosine Annealing)
- Batch size:64
- 最大训练 epoch:2000(含 early stopping)
- 损失函数:均方误差(MSE)
结构特点:
- 以 U-Net 为原型(Ronneberger et al., 2015)
- 将 U-Net 中特征图的 拼接(concatenation) 改为 残差加法(residual-style addition),融合来自两个分支的特征
- 每个网络由 3 个相同的 U-module block 堆叠而成
- 每个 U-module 内部有 MaxPooling(下采样)、卷积层、MaxUnpooling(上采样)和残差连接
- 额外设有输入层和输出层
- 所有卷积核大小为 3(输入输出层为 1)
为何选此架构:
- 论文通过消融实验证明,该架构相比 ResNet 精度高出约一个数量级
- 密集频谱回归(dense spectrum regression)任务中,U-Net 类变体通常是最有效的架构
五、主要实验结果与结论
5.1 三种典型材料结果(Au、TiO₂、Si)
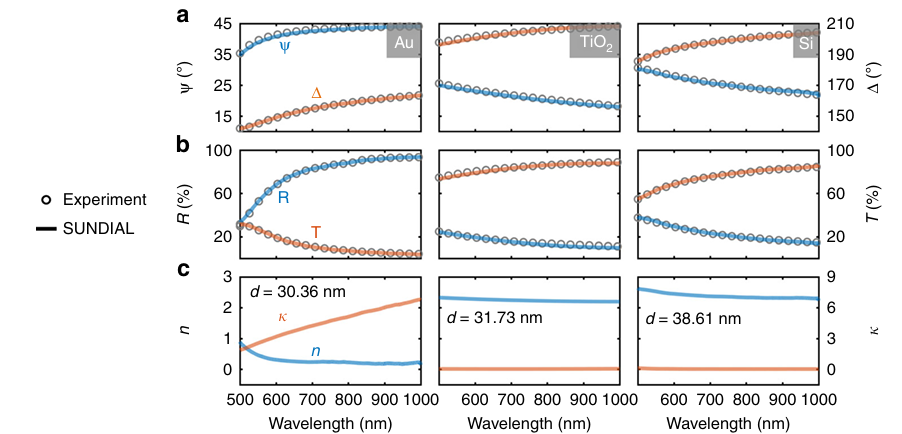
论文中 Fig. 3 展示了对金(Au)、二氧化钛(TiO₂)、硅(Si)的完整反演结果。SUNDIAL 输出的 $(n, \kappa)$ 色散曲线和厚度 $d$,通过正函数重建的 $(\Psi, \Delta, R, T)$ 与实测数据高度吻合(实线与空心圆几乎重合)。
5.2 与传统拟合方法的性能对比
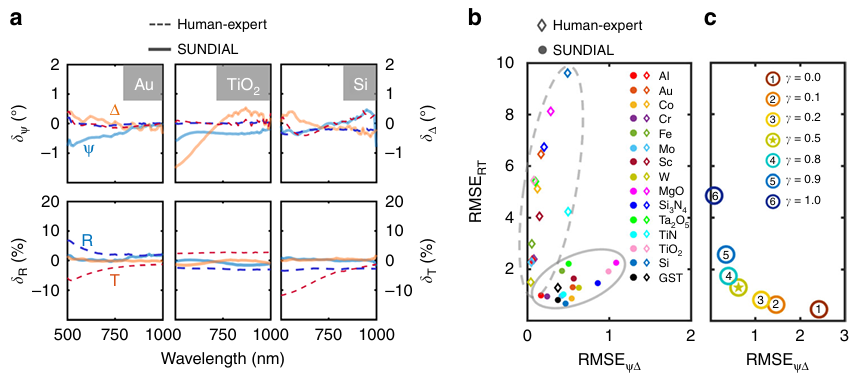
使用残差 $\delta_S = S_\text{cal} - S_\text{exp}$ 和 RMSE 定量比较:
\[\text{RMSE} = \sqrt{\frac{1}{N}\sum_{i=1}^{N}(S_i^\text{cal} - S_i^\text{exp})^2}\]关键发现:
- 传统方法(EP4Model)仅拟合 $(\Psi, \Delta)$,虽然椭偏角拟合良好($\delta_\Psi$, $\delta_\Delta$ 接近零),但 $\delta_R$, $\delta_T$ 显著偏离零(未约束的自由度)
- SUNDIAL 同时优化四路数据,$(\Psi, \Delta)$ 和 $(R, T)$ 的残差均接近零
- 在 RMSE 散点图(Fig. 4b)中,SUNDIAL 结果(实心点)明显更靠近原点,优于传统方法(空心菱形)
- 权重参数 $\gamma$ 的影响符合双目标优化的帕累托前沿规律,$\gamma = 0.5$ 在两路误差间取得最优平衡
5.3 鲁棒性
在模拟数据测试中(噪声水平分析):
- 当噪声水平 $N_r < 10^{-3}$ 时,SUNDIAL 表现良好:$(n, \kappa, d)$ 的 RMSE 约为 $5\times10^{-3}$, $3\times10^{-3}$, $0.8 \text{ nm}$
- 当 $N_r = 10^{-2}$ 时精度有所下降,但实验测量噪声 $\sigma < 6\times10^{-4}$,远低于容许噪声水平
与已有工作的对比定位
| 方法 | 是否需要专家干预 | 是否处理多解歧义 | 是否利用(R,T) | 是否全自动 |
|---|---|---|---|---|
| 传统迭代拟合(EP4Model 等) | 需要(初始猜测、色散模型选择) | 不能(依赖人工判断) | 辅助判断 | 否 |
| ANN 预处理(Urban & Tabet, 1994) | 减少但仍需 | 不能 | 否 | 部分 |
| SUNDIAL(本文) | 不需要 | 可以(自动消除) | 同时优化 | 完全自动 |
上述方法的局限性
- 计算速度:当前实现中每个样本需要 15 分钟至 1.5 小时(未优化),不适合实时在线检测
- 采样位置不一致:$(\Psi, \Delta)$ 和 $(R, T)$ 分别由椭偏仪和分光光度计在不同位置测量,可能引入系统误差,需升级仪器实现原位同步四路测量
- 训练数据覆盖范围:仅使用 200 种已知材料的 $(n, \kappa)$ 数据库训练,对数据库未收录的全新材料泛化能力待评估。←这也带来了它的一个局限性,只能适用于训练集里有的材料,给它训练集之外的材料,可能就反演不出来、精度很差or不物理(不符合kk关系)